One Last Squeeze of the LLM Orange?

After a long and much-hyped wait, OpenAI has finally released its new reasoning model, o1. According to its creators, the model can solve PhD-level physics problems, although they underline that this does not mean it is capable of conducting its own PhD research – a subtle, but important distinction.
I wanted to get a feel for the model's usefulness in my work context, so I asked it to implement the code I had just spent the previous five hours writing (already with the help of GPT-4o). It performed the task flawlessly in a blistering 27 seconds.
This was remarkable, but before we get too carried away, let me add a couple of caveats. First, much of the five hours I spent on the task was working out what I wanted to build, meaning I came to o1 having already figured out the fuzzy details. The second caveat is that I was working on a brand new project. (LLMs tend to excel at putting down the initial brush strokes, but their performance degrades when asked to complete the picture).
Nevertheless, o1's response gave me real pause for thought about the future.
When I returned from San Francisco back in March, I wrote in my month notes how struck I was by the unrealised potential of LLMs – that even if progress halted there and then, there would still a huge amount of value to be realised while we integrate LLMs into the economy.
My assumption was, of course, that progress would continue at pace (and, so, even more reason to think these unrealised gains would be significant), but in the subsequent months, we've instead seen AI labs get diminishing returns from scaling up the training of foundation models.
For some AI experts, that is inevitable. If they haven't already, LLMs will soon hit some kind of intelligence ceiling. After all, once a model has been trained on the entire corpus of human knowledge, what else is there for it to learn from? Synthetic data generated by the model itself? Not without causing model collapse.
In their view, the limitations of LLMs arise from how models develop their understanding of the real world. An LLM's conception of the world is formed within a metaphorical box, sealed from reality. Small bits of information get passed into that box from the outside world by humans acting as the model's eyes and ears. The problem with this approach is that our descriptions of the world are far less detailed and nuanced than our actual experiences in the world. To acquire human-like intelligence, models will need to be trained on enormous amounts of sensory data, and probably live in the real world as physical, experiencing agents.
While these experts see the curve of progress asymptotically rounding off at the threshold of human intelligence, others see an exponential curve hurtling into the realm of super-human intelligence.
Their view is that AI doesn't need to learn about the world from scratch, as humans have already summarised much of what they know about the world using language. This may still be a relatively small dataset compared to the amount of information consumed by humans in the evolutionary process that led to our intelligence (and indeed the emergence of language itself), but that is beside the point: so long as there is enough data for models to catch the statistical gist of intelligence, that may be enough to get the ball rolling.
It is against that backdrop that OpenAI has launched o1 – seemingly a little late given the expected rate of progress (it's well over a year since the launch of its last flagship model). Unlike the GPT-series of models, o1 is trained to produce reasoning steps, rather than answers. In essence, o1 is designed to replace humans as prompt engineers.
This new approach matters, not just because it produces much better answers than GPT-4, but also because it overcomes the apparent diminishing returns training foundation models.
OpenAI's initial attempts at building a reasoning model apparently involved training the model on human-generated chains of thought. This was later dropped in favour of training a model on chains of thought generated by GPT-4 itself, rewarding it for arriving at correct answers, and (it is believed) for taking the correct reasoning steps to get to that answer (presumably these are verified by a solver like Wolfram Alpha).
It's a journey that sounds notably familiar to the one that DeepMind went on with AlphaGo, first training it on expert human gameplay, and then later training it on moves it had generated itself. This culminated in the now infamous move 37 during its 2016 match against Lee Sedol – a pivotal moment that left Sedol visibly gobsmacked, and commentators astounded, remarking that it was a move "no human would ever play".
OpenAI's analysis of o1's scaling shows strong performance with increases in both train-time compute (the reinforcement learning that rewards correct reasoning steps) and test-time compute (the "thinking" time allocated to generate longer, more detailed answers).
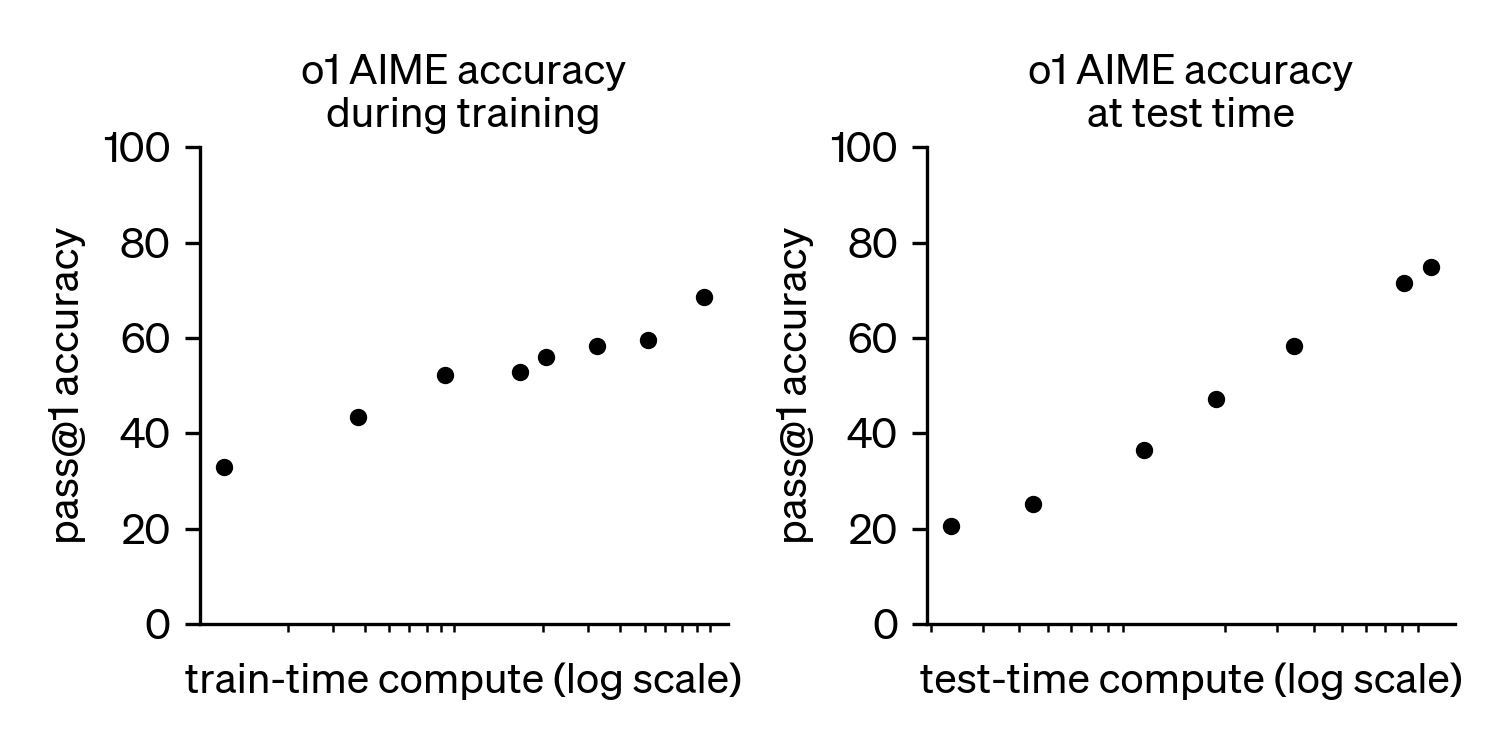
The key question now is whether those lines continue to trend up. Many AI researches certainly seem lit with excitement that reasoning models have a lot of headroom to grow. I am deeply curious in which domains they expect it to perform, and whether they foresee some kind of new intelligence emerging phenomenologically – an AGI equivalent of AlphaGo's move 37.
For now, the model seems to perform best when following clearly-defined paths, albeit very advanced ones. When I asked o1 to complete tasks with no obvious best answer, it showed little more wisdom than GPT-4. When I asked o1 to complete a moderately difficult coding task that, as far as I know, has no published solution, its answer was, to use the academic term, bullshit. I suspect we'll see mixed results for questions like this – some absurd, others sublime.
So, model performance appears limited to well-defined and verifiable domains like maths, physics, and the aspects of coding with less room for interpretation. But unlike a PhD in physics, whose first-principles thinking places her in high demand for jobs across a wide range of fields, the reasoning o1 acquired from its training is not translating to intelligence in other areas.
This tallies with OpenAI's own benchmarks showing o1 performing poorly in subjective areas, which don't have clear cut answers available for the model to verify against.
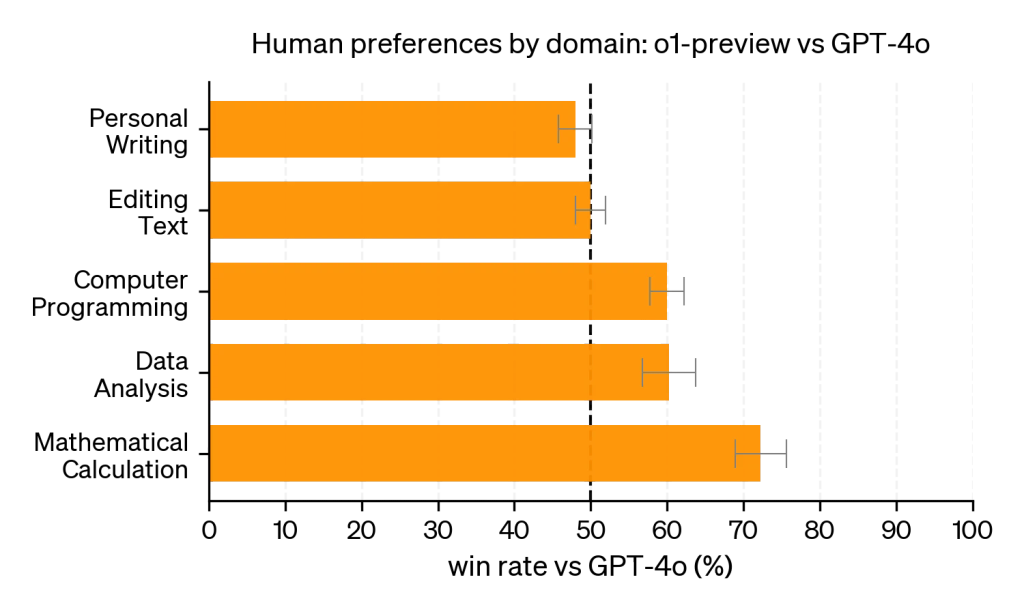
Whatever o1's deficits, it is a remarkable breakthrough, and we can only expect its capabilities in hard technical subjects to improve. Exactly how much more intelligence can be squeezed out of LLMs still remains to be seen. It is still speculative whether reasoning skills gained from training LLMs on known solutions will lead to breakthroughs in the unknown.
For most people though, the most pressing question is not whether LLMs will solve maths and physics in their entirety (although that would be very cool), but, rather, the existential one – will they continue working alongside AI, or get replaced by it? That depends on whether models can get a proper grasp of the mundane, fuzzy reasoning that humans use minute-by-minute in the real world. As of today, this still appears far out of their reach.
Thanks for reading! If you enjoyed this, subscribe for free to get next month's post delivered direct to your inbox.