Always Building, Never Shipping

It is winter in Narnia, and has been for ever so long…. always winter, but never Christmas.
When vibe coding was taking off, I quipped that it used to take years, but now you can generate a legacy codebase in just a few hours.
Well, the joke's on me. I am now father to over a million lines of lovingly generated code that I cannot possibly continue to maintain.
This is not an anti-AI piece. It is is an honest write-up of what I built and learned. I enjoy trad coding; I enjoy agentic engineering. My identity isn't attached to either. I just want to make good things.
But I need to be honest: after three months of not writing any code, I'm now exhausted. Each new change fans out into even more work. The cost of maintenance outweighs my budget for purchasing tokens. On the current trajectory, this code will never be production ready. So I'm declaring bankruptcy.
I hope that drawing a line under this experiment will help me figure out a better way.
Project 1: The Scientist
https://github.com/djgrant/the-scientist
First things first: you gotta build your own agent harness.
The Scientist came about from my frustration with micro-managing agents.
I wondered whether forcing agents to use the scientific method (state a hypothesis, decide how to verify, iterate) might yield good results for long-horizon tasks.
I set up some skills and sub-agents and left it running overnight to work on an idea. When I came back in the morning, I was blown away.
Project 2: MDZ
https://github.com/djgrant/mdz
Here's what happened: for The Scientist, I wanted a map-reduce skill that could be used generically by other skills. Essentially functional composition for skills.
I had noticed that models underperform and cheat when given broad instructions like, "run this set of simplification heuristics against the supplied problem, then pick the best solution". Getting reliable results for a request like this requires task decomposition and sub-agents.
It struck me that using a formal grammar to express my desired workflow might improve performance. I ran a quick benchmark, and it turns out this works. Agents are actually pretty good at evaluating programs.
I drafted a very basic language spec – a superset of markdown designed for agents – used the language to write the prompts I needed for The Scientist, and used The Scientist to build the language.
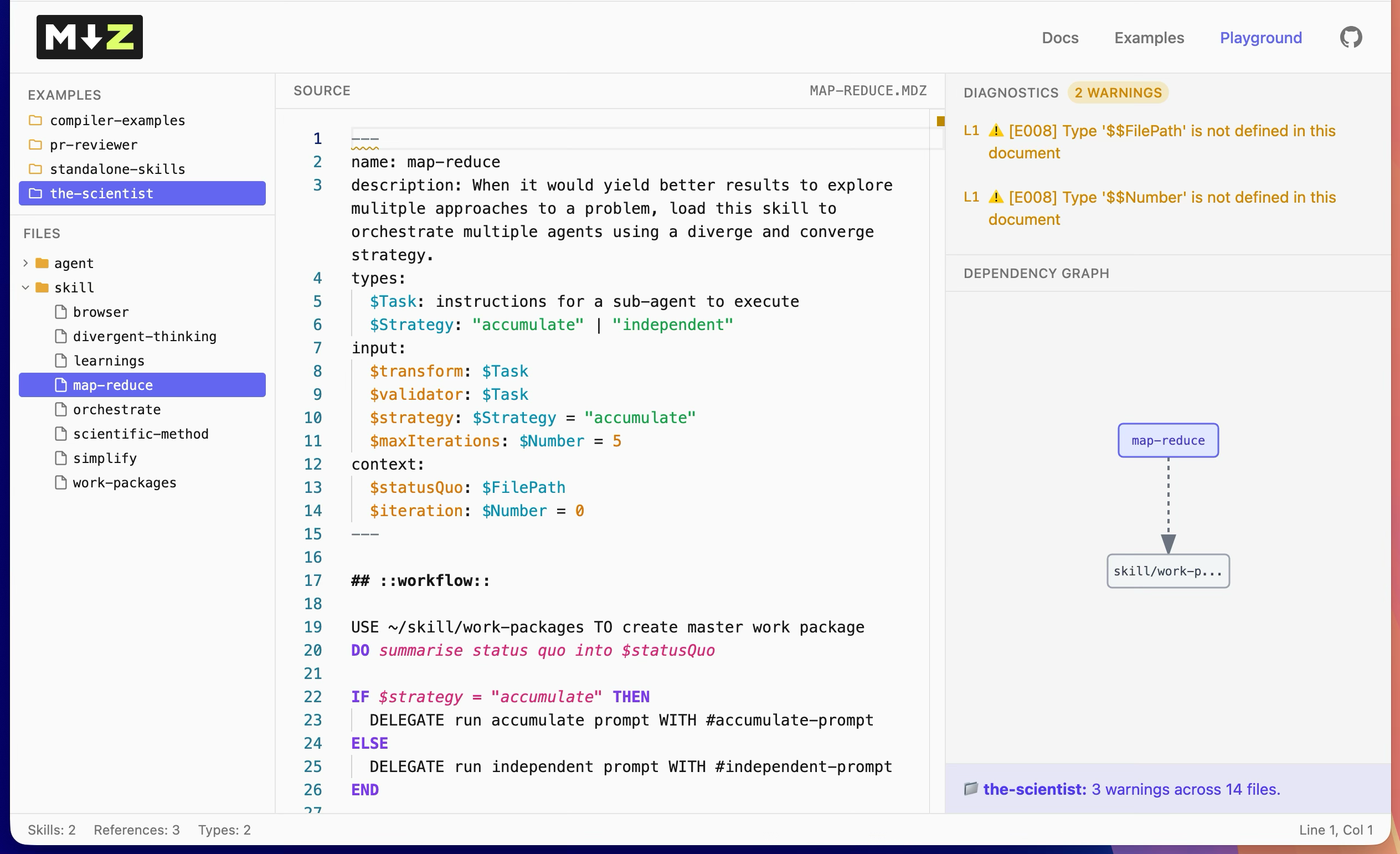
The screenshot is close to what I woke up to the next morning. A fully working playground for my new language, built from the ground up with a custom grammar, parser, syntax highlighter, linter and language server.
The language worked, the harness worked. I was away to the races. I was away with the fairies.
It wasn't until a few weeks later that I looked under the hood and realised the implementation was garbage. (I have since thrown it away and rewritten the spec from scratch).
Aside: A JPEG Analogy
In the old days, software projects would materialise one slice at a time. Once all the slices were built, the project was complete.

With AI, you get whole thing all at once. You're stunned. "Omg, this would have taken me weeks!" Then you squint, and notice it's only superficially functional.

The AI-generated project becomes production-ready once that initially blurry picture is pulled into focus. Easier said than done.
When you build software slice by slice, you naturally develop a deep mental model of how and why the system works. AI lets you skips that step and just hands you a complete codebase, making it incredibly hard to spot, let alone fix, its underlying flaws.
But worse, seeing the full picture triggers a dopamine hit. The motivation to push through the tedium of wrangling code is replaced with an urge to add more rainbows and ponies.
This is the trap that leaves you always building and never shipping.
Project 3: pok
https://github.com/djgrant/pok
Pok came about after I noticed how much I was leaning on agents to execute bash commands for me. This was clearly a bad habit because writing the prompt is invariably more keystrokes than actually typing the command, and mediating a local command via a cloud-hosted LLM is always going to be slower.
Pok is like Next.js but for CLIs. You put your commands and sub-commands in a directory, and they magically become an app in your terminal.
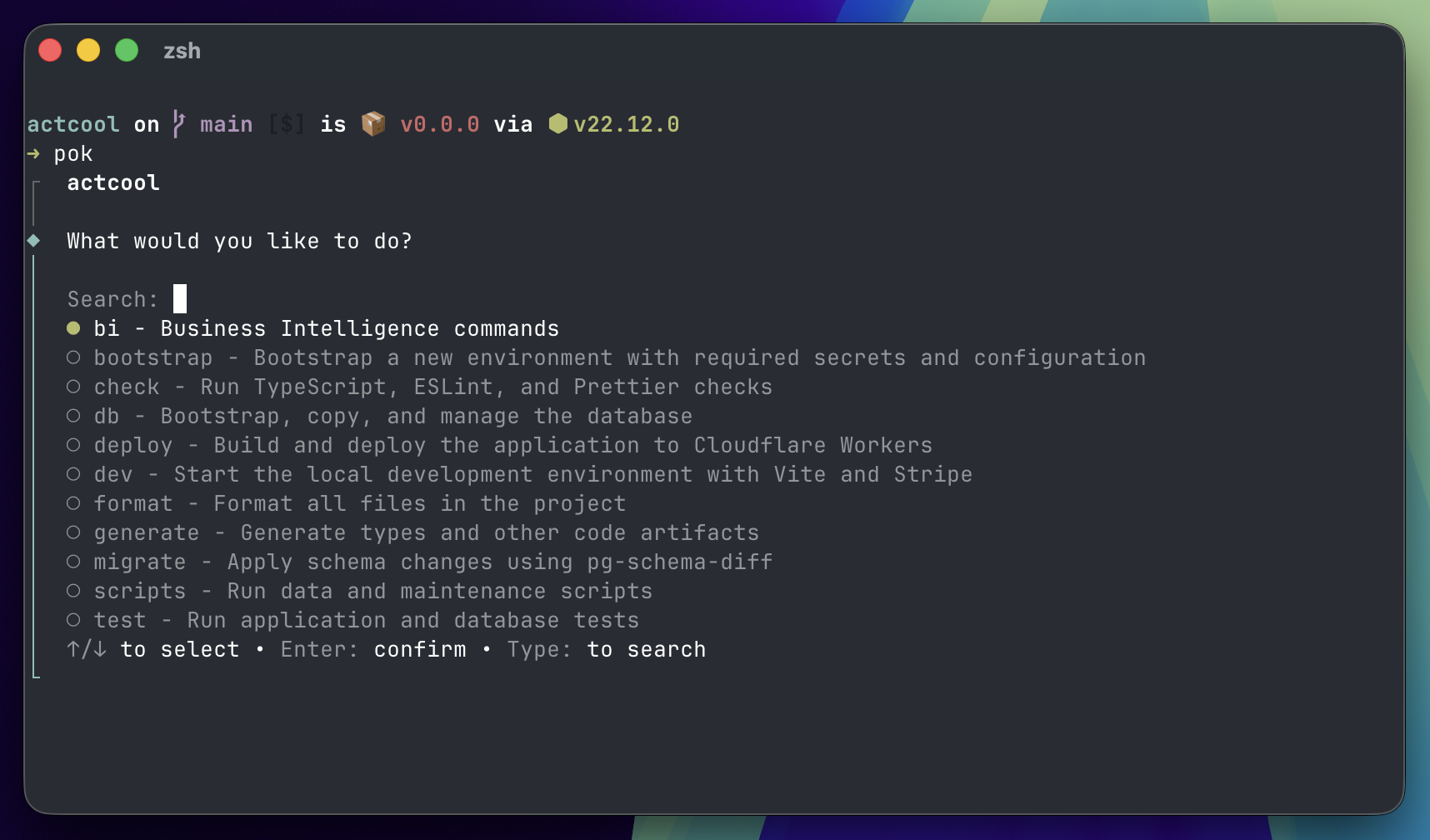
It's designed for dual use by humans an agents. It treats secrets as a first-class concern, which has enabled me to eliminate env files from my machine (reassuring when you've got agents yoloing all over the place). It has a plugin architecture to support different TUIs/GUIs.
I called this tool Pok because I type it so frequently, and p-o-k rolls off the fingers beautifully.
Of all the projects I've built, Pok is the one I do recommend trying. It's still alpha software, but after using it for a few months I can't go without it.
Project 4: piq
https://github.com/djgrant/piq
By this point, I was waking up to the agent psychosis tells – the feeling of being on the cusp of something great, an unhealthy parasocial relationship with the planning agent, a vast collection of markdown documents.
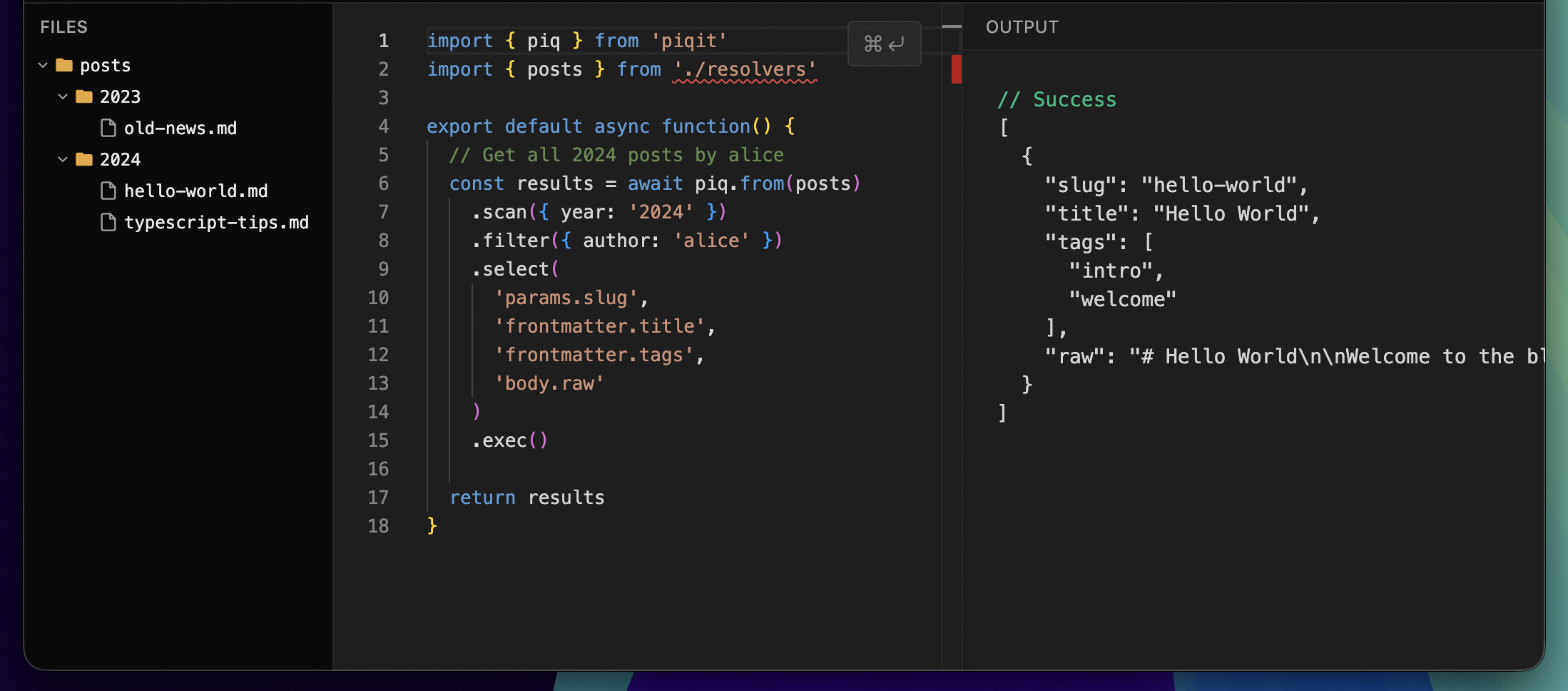
Piq began as a way to easily query those documents, inspired by Astro loaders, but evolving into a fully-fledged typed SDK for document storage. In every respect, it is the anti-GraphQL.
It's simple and fast. The code probably isn't a work of art, but the API is neat.
Project 5: looped
Looped is project management software for agents. It's a Pok app, and uses Piq to efficiently query large collections of markdown files.
The idea is that "workers" (codex, amp, claude code, whatever) run in a loop and pick up the next task.
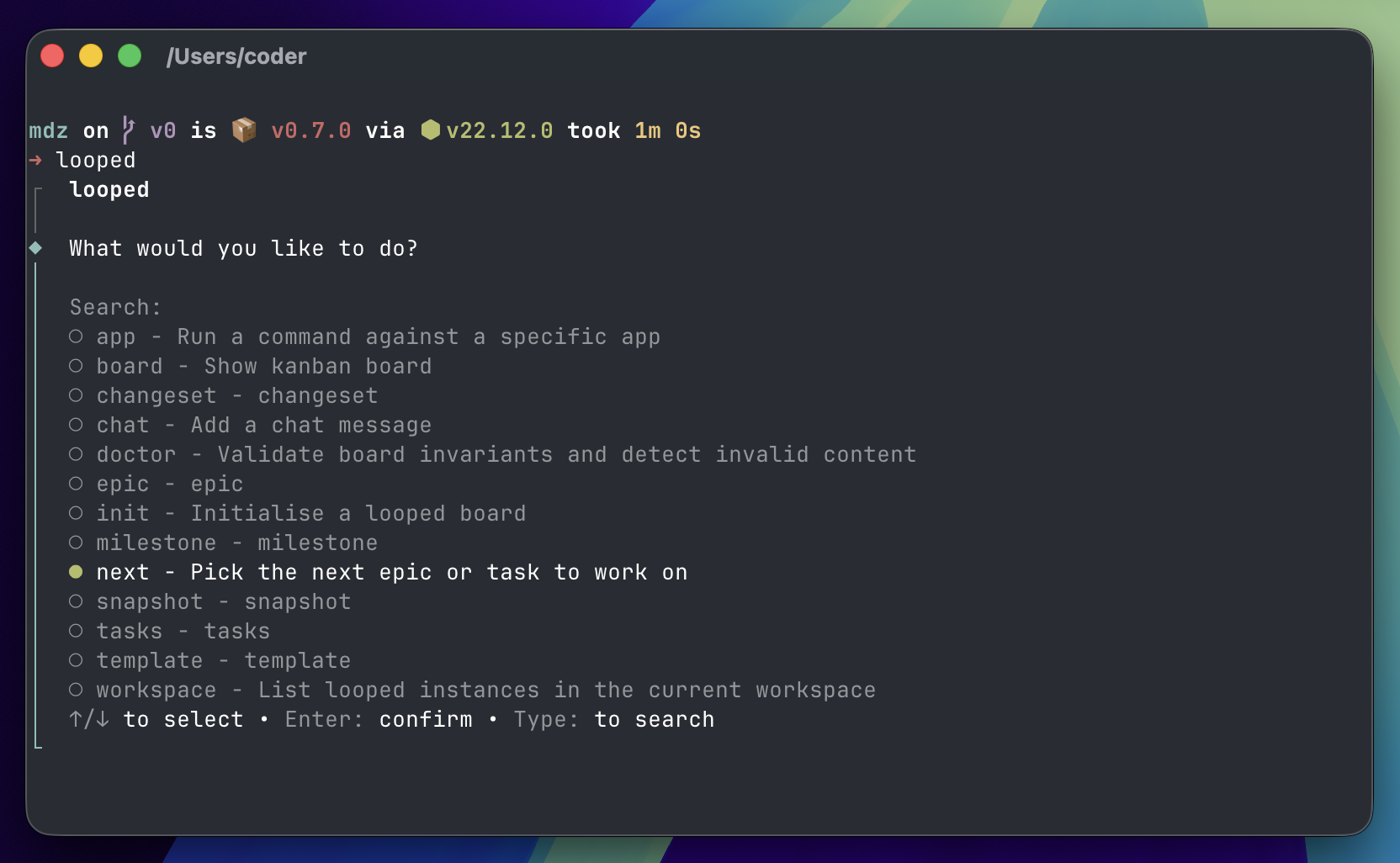
I didn't need to build this. I could have used Linear/Todoist/Github/Beads, but there was one big itch I wanted to scratch: tracking each agent's reasons for making a change.
One approach to this problem is to simply record the entire agent conversation. But finding out why an agent has done something after the fact is problematic.
Agents do not know why they do things. Sure, if you ask them, they will give you an answer, but that answer will be a post-rationalisation based on whatever is in their context window, rather than recollections of real thoughts, feelings and events leading up to its decision.
With Looped, I wanted to test if prompting an agent to report it's decision-making before acting would result in more grounded reasoning traces, and perhaps even better decisions.
Project 6: Smithers
Smithers is the final layer – a place for me to plan and review agents' work.
I particularly wanted to crack the handoff where, after completing a task, the agent hands me an executive report, synthesising its changes.
Everyone agrees that, at the new pace of code generation, humans cannot possibly review code the old way.
The pull request is dead. Peer review has never been more important.

Smithers has a structured system for transforming the decision stream recorded by Looped into a meaningful changeset that a human can quickly review.
If I learned anything from this whole exploration, it's that preserving a mental model of the code, and staying on top of agents decisions is vital. I probably should have built this tool first!
After several months hacking with AI agents, I created a heap of code that I can no longer maintain. The code is indelibly mine – a byproduct of my creativity – yet most of it I have never read. The bits I have read, look alien and out of place.
That would probably be fine but for the fact that my productivity has been decimated. The initial excitement I felt when my ideas materialised before my eyes is now replaced with frustration. I just want to open an IDE and make the computer do the thing I imagined in my mind. I want to get back to creating.

Thanks for reading! If you enjoyed this, subscribe for free to get next month's post delivered direct to your inbox.